
Beyond Supervised Learning: Unlocking AI's Potential with Reinforcement Learning
Understand the fundamental shift RL offers, its core components, real-world applications, and the advanced challenges driving the future of intelligent systems.

Introduction
Imagine AI systems that learn not from pre-labeled data, but through iterative trial and error, autonomously mastering complex tasks by interacting with their environment. This is the essence of Reinforcement Learning (RL), a transformative paradigm driving the next wave of artificial intelligence. This deep dive will unravel the core principles of RL, explore how its powerful merger with deep neural networks has unlocked unprecedented capabilities, and showcase its diverse applications across industries, ultimately touching upon the frontier challenges shaping its future.

Understanding Reinforcement Learning: A Paradigm Shift in AI
Artificial Intelligence (AI) and Machine Learning (ML) are rapidly transforming various domains. While Supervised Learning has demonstrated remarkable success in tasks requiring extensive labeled datasets, a distinct paradigm, Reinforcement Learning (RL), provides a compelling alternative. RL empowers intelligent agents to acquire optimal behaviors through iterative trial and error within complex, dynamic environments. This section establishes the foundational concepts of Reinforcement Learning, highlighting its unique approach and differentiating it from traditional machine learning paradigms.
Supervised Learning vs. Reinforcement Learning: Key Differences and Limitations
Supervised Learning operates on the principle of learning from labeled examples. A model is trained to map input features to known output labels, minimizing a predefined error function. This approach excels in tasks such as image classification, natural language processing, and regression where ample ground truth data is available, allowing the model to learn a direct mapping between inputs and desired outputs.
In contrast, Reinforcement Learning does not rely on pre-existing labeled datasets. Instead, an RL agent learns by interacting directly with an environment. The agent receives scalar feedback in the form of rewards or penalties for its actions, aiming to maximize a cumulative reward signal over time. This paradigm is particularly suited for sequential decision-making problems, where the optimal action depends on the current state and crucially influences future states and subsequent rewards. Limitations of supervised learning often arise in scenarios requiring strategic decision-making, where the "correct" answer for every possible state-action pair is not explicitly provided, or where the optimal behavior emerges from a sequence of interactions rather than isolated mappings. RL directly addresses these challenges by enabling autonomous learning through experience.
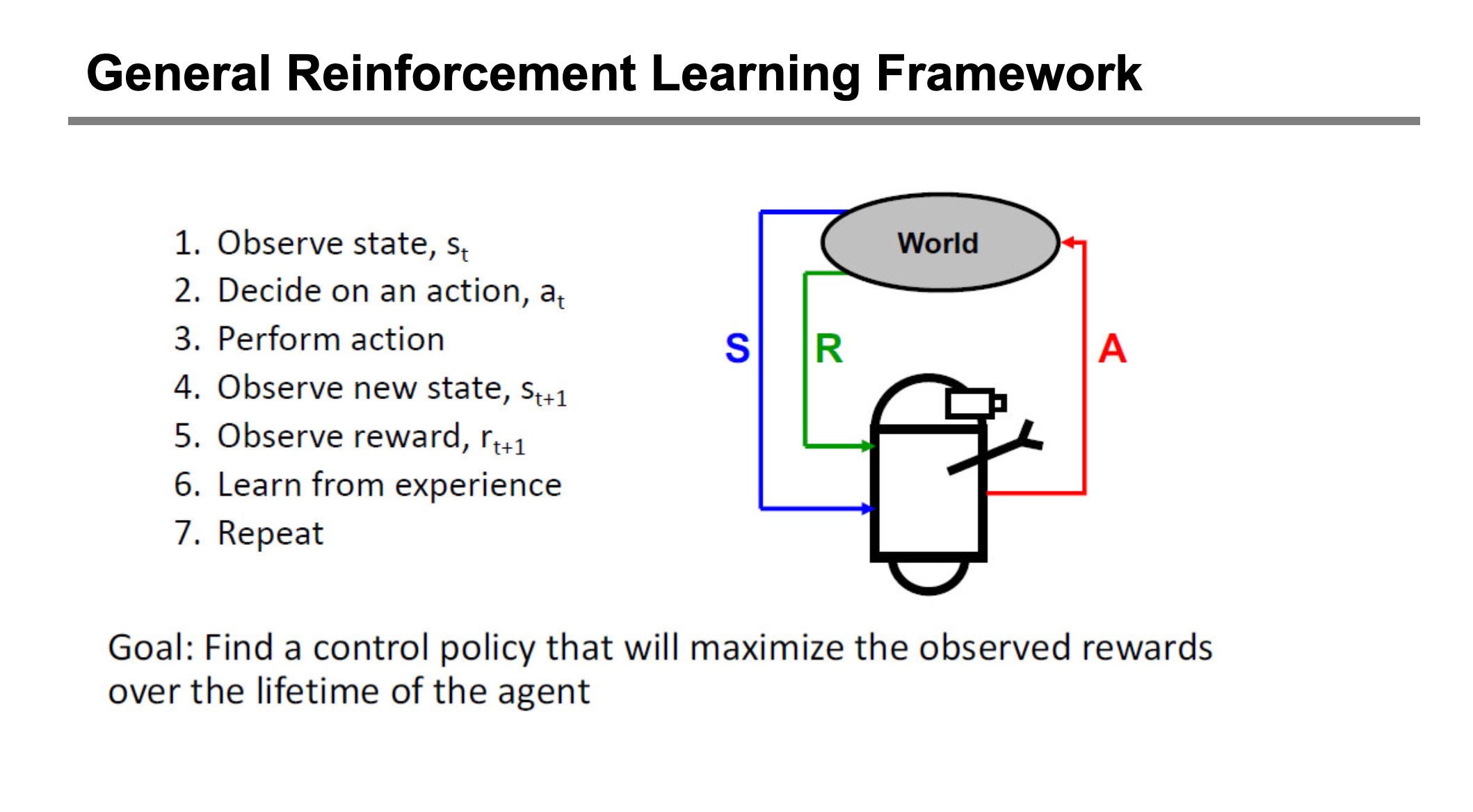
The Core Components of Reinforcement Learning
An RL system comprises several fundamental elements working in concert to facilitate learning and decision-making:
Agent: The learner or decision-maker. The agent observes the environment's state and selects actions based on its learned policy.
Environment: The external world with which the agent interacts. It encompasses the rules of interaction, the possible states the agent can be in, and the reward signals provided in response to the agent's actions.
State: A complete, or sufficiently informative, description of the environment at a given moment. The agent's decision-making process is fundamentally based on its perception or representation of the current state.
Action: A specific move or decision made by the agent that influences the environment's state. Actions are the means by which the agent interacts with and changes its surroundings.
Reward: A scalar feedback signal provided by the environment to the agent after an action. This signal quantifies the immediate desirability of the agent's action in that particular state. The agent's primary objective is to maximize its total accumulated reward over the long term.
Policy: The agent's strategy or behavior function. It defines how the agent maps observed states to actions. An optimal policy dictates the best action to take in any given state to maximize long-term cumulative reward.
Consider a robotic arm learning to pick up an object. The robotic arm itself is the agent. The physical world, including the object's position, the table, and gravity, constitutes the environment. The arm's joint angles, the gripper's status, and the object's coordinates represent the current state. Moving a joint or opening/closing the gripper are actions. A positive reward is received when the object is successfully grasped, while a negative reward might be given if the object is dropped or if the arm collides with an obstacle. The arm's learned strategy for moving its joints and operating its gripper to consistently grasp objects is its policy.
The Credit Assignment Problem: Learning from Delayed Rewards
A central challenge in Reinforcement Learning is the credit assignment problem. Unlike supervised learning, where feedback (the correct label or value) is immediate for each prediction, RL agents often receive rewards that are delayed and sparse. An action taken at a specific time step might only contribute to a significant positive (or negative) reward much later in the sequence of interactions. Determining which past actions were truly responsible for a future outcome becomes a non-trivial task.
The agent's goal is to maximize the cumulative reward over an entire episode or its lifetime, not just immediate rewards. This necessitates that the agent learns the long-term consequences of its actions, effectively assigning credit or blame to actions that contributed to these delayed outcomes. Overcoming the credit assignment problem is fundamental to developing effective RL policies, enabling agents to learn complex, optimal behaviors even when feedback is sparse and arrives long after the causative actions.
The Rise of Deep Reinforcement Learning: Combining Data and Optimization
The previous section established the foundational concepts of Reinforcement Learning (RL), differentiating it from supervised learning and outlining its core components. This section explores the pivotal advancements that led to the emergence of Deep Reinforcement Learning (Deep RL), a powerful paradigm that combines the perceptual capabilities of deep neural networks with the decision-making frameworks of classical RL, fundamentally transforming the field of AI.
The Revolution of Deep Learning: Feature Extraction and Generative Models
Deep Learning fundamentally transformed the field of Artificial Intelligence by enabling models to learn intricate, hierarchical representations directly from raw, high-dimensional data. Prior to the Deep Learning revolution, extracting meaningful features from raw inputs—a crucial step for any AI model—was often a manual and laborious process known as feature engineering. This reliance on human expertise and domain-specific knowledge presented a significant bottleneck for scalability and generalization.
Deep neural networks, particularly convolutional neural networks (CNNs) for image data and recurrent neural networks (RNNs) for sequential data, demonstrated unprecedented capabilities in automatically learning and extracting abstract features from high-dimensional inputs without explicit human programming. This allowed models to identify complex patterns and abstract representations from data like pixels or raw audio, a capability indispensable for an RL agent operating in realistic environments. Furthermore, advancements in generative models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), showcased deep learning's power in synthesizing realistic data, a capability that indirectly contributes to robust training through data augmentation or the development of more accurate environment models in complex RL scenarios. These breakthroughs in automatic perception and representation learning laid the essential groundwork for integrating deep neural networks into RL agents, enabling them to process the complex sensory information of the real world.
Historical Roots of Modern Reinforcement Learning: Classical RL and Control Optimization
Reinforcement Learning boasts a rich history that significantly predates the Deep Learning revolution. Classical RL algorithms, such as Q-learning and SARSA, provided foundational theoretical frameworks for how an agent could learn to maximize cumulative rewards through iterative trial and error. These methods focused on learning optimal value functions (estimating the goodness of states or state-action pairs) or policies (direct mappings from states to actions) primarily in discrete, often finite, state-action spaces. They effectively addressed challenges like the credit assignment problem, where an agent must determine which past actions were responsible for a delayed reward.
Concurrently, the mature field of optimal control theory, deeply rooted in mathematics and engineering, developed robust methods for designing controllers that optimize system behavior over time. Techniques like dynamic programming provided rigorous frameworks for sequential decision-making, often assuming a complete and accurate model of the environment. While highly effective in well-defined, lower-dimensional problems with clear state representations, these classical approaches faced significant scalability challenges. They struggled immensely when confronted with high-dimensional state spaces (e.g., raw pixel inputs), continuous action spaces (e.g., robotic joint torques), or complex, unknown environments where a perfect model was unavailable or intractable to define. This "curse of dimensionality" was a primary barrier to applying RL to real-world complexities.
Deep Reinforcement Learning (Deep RL): Merging Perception with Decision-Making
Deep Reinforcement Learning emerged as a powerful paradigm from the synergistic combination of Deep Learning's unparalleled representation learning capabilities and Reinforcement Learning's robust decision-making frameworks. This merger directly addressed the critical scalability limitations that plagued classical RL algorithms. By employing deep neural networks as highly flexible and powerful function approximators, Deep RL agents can effectively handle high-dimensional, raw sensory inputs such as pixels from a camera, raw audio signals, or complex sensor readings.
In this integrated architecture, the deep neural network serves as the "perception" layer. It processes the raw observations, automatically extracting meaningful, abstract features and representations that are crucial for understanding the environment's state. Subsequently, the classical RL algorithms leverage these rich, learned representations to learn optimal "decision-making" strategies. The deep network can approximate complex non-linear mappings from states to actions, value functions, or even environment models, allowing the agent to generalize from a limited set of experiences. This profound integration allowed RL to move far beyond tabular methods and simple, hand-engineered state representations, enabling agents to learn directly from raw sensor data and operate effectively in highly complex, realistic, and previously intractable environments.
Pioneering Achievements: From AlphaGo's 'Move 37' to Emergent Behaviors and 'The Bitter Lesson'
The advent of Deep RL ushered in a series of groundbreaking achievements that not only captured widespread public attention but also profoundly demonstrated the paradigm's immense potential. A landmark success was DeepMind's Deep Q-Network (DQN), which achieved human-level performance across a diverse suite of Atari 2600 video games by learning directly from raw pixel inputs, showcasing the power of end-to-end learning.
A more profound milestone, however, was AlphaGo's historic victory over the world champion Go player, Lee Sedol. Notably, Move 37 in Game 2, an unconventional and seemingly counter-intuitive move, demonstrated a level of strategic intuition and creativity previously thought exclusive to human masters. This achievement highlighted Deep RL's capacity for complex, long-term planning and its ability to discover novel, highly effective strategies in domains with immense state spaces.
Beyond specific games, Deep RL has enabled the emergence of sophisticated and often surprising behaviors in diverse domains, including complex robotic control, multi-agent coordination, and intricate simulations. These successes frequently involve agents discovering non-intuitive or highly optimized solutions that surpass human-designed approaches. These groundbreaking achievements collectively underscore "The Bitter Lesson," a concept emphasizing that general methods that leverage massive amounts of computation and data scale more effectively and ultimately outperform human-designed knowledge or handcrafted features, reinforcing the power of end-to-end learning in complex domains.
RL in Action: Diverse Applications Across Industries
The previous sections established the foundational principles of Reinforcement Learning (RL) and explored the transformative impact of Deep Learning on its capabilities. With a robust understanding of how RL agents learn optimal behaviors through interaction and cumulative reward, this section now shifts focus to the practical deployment of RL across various industries.
Reinforcement Learning's inherent ability to navigate complex, dynamic environments and solve sequential decision-making problems makes it uniquely suited for a wide array of real-world applications. Its versatility allows it to not only optimize existing processes and discover novel strategies but also to enable autonomous agents in scenarios where traditional, rule-based methods fall short due to the sheer complexity or uncertainty of the environment. RL's capacity for adaptive learning from experience is key to its success in these diverse domains.
The following areas represent significant domains where Reinforcement Learning is actively being applied:
Game Playing and Robotics: Mastering Complex Control and Emergent Behaviors
Reinforcement Learning has demonstrated remarkable success in mastering complex games, often surpassing human capabilities. These environments provide structured, yet highly dynamic, scenarios with clear reward signals, allowing agents to learn optimal policies for navigating vast state-action spaces. Similarly, in robotics, RL enables agents to learn intricate motor control and develop sophisticated behaviors directly from interaction with physical or simulated environments. This includes tasks ranging from manipulation and locomotion to complex navigation, where the agent learns to adapt its actions based on real-time sensory input to achieve desired objectives.
Healthcare and Finance: Optimizing Decisions in Critical Domains
In critical sectors such as healthcare and finance, RL offers powerful tools for optimizing decision-making processes under uncertainty. In healthcare, potential applications include personalizing treatment recommendations by adapting to patient responses over time, optimizing drug discovery pipelines through iterative experimentation, and managing chronic diseases with dynamic intervention strategies. In finance, RL can be applied to develop adaptive trading strategies, optimize portfolio allocation, and enhance risk management by learning from market dynamics and making sequential decisions that aim to maximize long-term returns while mitigating exposure. The ability of RL to account for long-term consequences and stochastic environments is particularly valuable here.
Recommender Systems and Resource Management: Personalized Experiences and Efficiency
RL's capacity for sequential decision-making extends to enhancing user experiences and optimizing resource allocation. In recommender systems, RL agents can learn to suggest items that not only satisfy immediate user preferences but also maximize long-term user engagement and satisfaction by understanding the evolving user journey and predicting future interactions. For resource management, RL can optimize complex systems such as energy consumption in smart grids, traffic flow in urban networks, or logistical operations in supply chains. By making adaptive decisions based on real-time data and environmental feedback, RL agents can improve efficiency, reduce waste, and enhance system performance dynamically.
Beyond Traditional Fields: New Frontiers of Reinforcement Learning Application
The applicability of Reinforcement Learning continues to expand beyond these established domains, demonstrating its profound versatility. New frontiers are constantly being explored, showcasing RL's potential to address novel challenges in areas ranging from accelerated scientific discovery and materials design to intelligent infrastructure management and smart cities. In these emerging fields, RL's core principle of learning optimal actions through interaction—even when the optimal path is unknown or the environment is highly complex—remains a powerful paradigm for solving increasingly intricate problems and driving innovation.
Beyond the Basics: Advanced Concepts and Future Challenges in Deep Reinforcement Learning
The previous sections established the foundational principles and diverse applications of Reinforcement Learning (RL) and Deep Reinforcement Learning (Deep RL). While Deep RL has achieved remarkable successes, its deployment in complex, real-world scenarios still presents significant challenges. This section explores advanced concepts and addresses key limitations, outlining the future trajectory of Deep RL and its role in the pursuit of Artificial General Intelligence (AGI).
Addressing Limitations: Sparse Rewards and Sample Efficiency
A primary challenge in many complex RL environments is the issue of sparse rewards. In such scenarios, positive feedback is infrequent or only occurs at the culmination of a long sequence of actions, making it difficult for an agent to learn which actions contributed to the eventual success. For example, in a complex robotic assembly task, a reward might only be given upon successful completion of the entire assembly, rather than for each intermediate step. This sparsity significantly complicates the credit assignment problem, where the agent struggles to attribute success or failure to specific preceding actions. Without clear, frequent signals, the learning process can be extremely slow or even fail to converge on an effective policy.
Closely related is sample efficiency. Deep RL algorithms often require an immense number of interactions with the environment to learn an effective policy. This extensive data requirement can be prohibitive in real-world applications where interactions are costly, time-consuming, or unsafe (e.g., in robotics for physical damage or in healthcare for patient safety). Research in this area focuses on developing methods that enable agents to learn effectively from limited experience, such as experience replay enhancements, model-based RL, and curriculum learning, although specific methodologies are beyond the scope of this discussion. Improving sample efficiency is crucial for making Deep RL practical for real-world deployment.
Learning from Others: Imitation Learning and Inverse Reinforcement Learning
When direct reward engineering is challenging or expert demonstrations are readily available, alternative paradigms like Imitation Learning (IL) and Inverse Reinforcement Learning (IRL) become valuable. Imitation Learning allows an agent to learn a policy by observing and mimicking an expert's behavior. Conceptually, this treats the problem as a supervised learning task where the expert's observations are inputs and their corresponding actions are the desired outputs (labels). This approach bypasses the need for a manually designed reward function altogether, directly learning a behavioral policy from demonstrations.
Inverse Reinforcement Learning takes a different, more profound approach. Instead of learning a policy from a predefined reward, IRL aims to infer the underlying reward function that best explains an observed expert's behavior. The premise is that the expert is acting optimally with respect to some unknown reward function. Once this implicit reward function is inferred, standard RL algorithms can then be applied to optimize a policy for that learned reward. Both IL and IRL offer powerful ways to leverage human expertise to accelerate and simplify the learning process for complex tasks, especially where specifying explicit rewards is impractical.
Adapting and Transferring Knowledge: Transfer Learning and Meta-learning ('Learning to Learn')
For RL agents to be truly versatile and efficient, they must possess the ability to adapt to new tasks and environments without starting from scratch. Transfer Learning in RL involves leveraging knowledge acquired from solving one task or in one environment to improve learning performance on a different, but related, task or environment. This can manifest as pre-training a policy or value function on a simpler or related task, or transferring learned features and representations that are broadly applicable. The goal is to reduce the training time and data required for new tasks by capitalizing on previously gained insights.
Meta-learning, often referred to as "learning to learn," pushes this concept further. A meta-learning agent is trained across a distribution of tasks such that it can quickly adapt to a new, unseen task with minimal additional training data or interactions. This involves learning general learning strategies, optimal initialization parameters, or efficient optimization procedures that enable rapid adaptation to novel situations. Unlike traditional transfer learning which reuses learned knowledge, meta-learning focuses on learning how to learn effectively across a family of tasks. These approaches are critical for achieving greater generalization and reducing the prohibitive sample complexity often associated with training agents for diverse real-world applications.
The Path to General Intelligence: Reinforcement Learning with Human Feedback (RLHF) and Current Challenges
Reinforcement Learning plays a pivotal role in the ongoing pursuit of Artificial General Intelligence (AGI). A key development in this direction, particularly for large language models (LLMs), is Reinforcement Learning with Human Feedback (RLHF). RLHF involves fine-tuning a model (e.g., an LLM) using human preferences as a reward signal. Humans provide feedback by rating the quality, helpfulness, or safety of different model outputs. An RL agent then learns a policy that aligns the model's behavior more closely with human values and intentions, effectively "teaching" the model what constitutes a good response. This approach has been instrumental in making LLMs more helpful, harmless, and honest, demonstrating RL's power in aligning complex AI systems with human objectives.
Despite these advancements, significant conceptual and practical challenges remain on the path to AGI. These include developing agents that can robustly handle open-ended, ill-defined problems, exhibit common-sense reasoning, and possess true understanding beyond mere pattern matching or statistical correlation. While RL provides a powerful framework for learning complex behaviors, further research is essential to overcome current limitations and unlock its full potential in creating adaptable, truly intelligent systems capable of tackling the most complex real-world problems.
Conclusion
Reinforcement Learning, especially Deep RL, has emerged as a transformative force in AI, empowering intelligent agents to learn optimal behaviors through iterative interaction and cumulative reward in complex, dynamic environments. Its fusion with deep neural networks has overcome previous limitations, leading to groundbreaking achievements across diverse domains from gaming and robotics to healthcare and finance. While challenges like sample efficiency and sparse rewards remain, ongoing research into advanced techniques such as transfer learning and RLHF is continually expanding its capabilities. As we push these frontiers, RL is set to be a cornerstone in developing more adaptable, truly intelligent systems and advancing the path towards Artificial General Intelligence.