
Decoding the Art: Understanding Text Generation with Transformers - I
#8 Advanced Generative AI: Exploring Text Generation Techniques with Transformers - Part I

Introduction
One of the most remarkable abilities of transformer models is their capacity to generate text that closely mimics human writing. With extensive training, large language models (LLMs) like GPT-3 can develop a wide range of skills for understanding and recognizing patterns in the text they've been trained on. These skills can be harnessed through various input prompts. In this blog, let’s delve into different text generation techniques using transformer-based models and examine how various hyperparameters play a crucial role in shaping the LLM's response to a given prompt.

Understanding Text Generation in Transformers
The decoder component of a transformer model primarily facilitates text generation. The decoder iteratively produces tokens based on the input prompt until they reach the specified length. This process, known as conditional text generation, depends on the input prompt to shape the output sequence.
The decoding method is central to this mechanism, which determines the selection of tokens from the vocabulary at each timestep. Various decoding techniques, each with its own set of hyperparameters, can be employed to achieve the desired output for a given prompt. In this blog, let’s explore some of these methods and their impact on text generation.
Exploring Text Generation Techniques
1. Greedy Search Decoding
Greedy search decoding is the most basic method used in text generation. This approach is characterized by its simplicity and speed, as it makes decisions based solely on the immediate next token without considering the overall sequence.
How Greedy Search Works
It selects the token with the highest probability, or logits, at each timestep.
This approach is straightforward and can quickly generate text.
Implementation
Greedy Search can be implemented using the transformers library by setting the do_sample parameter to False in the generate() function. We can also specify the maximum number of tokens generated by setting the max_new_tokens parameter.
Below is an example of how to implement greedy search decoding with the GPT-2 XL model using the transformers library:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Setup the model and tokenizer
checkpoint = "gpt2-xl"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
# Encode the inputs
input_text = "Once upon a time, there was a"
input_ids = tokenizer(input_text, return_tensors="pt")["input_ids"].to(device)
# Generate output using Greedy Search
output = model.generate(input_ids, max_new_tokens=70, do_sample=False)
generated_text = tokenizer.decode(output[0])
print(generated_text)Code Output:
Once upon a time, there was a man named John. John was a man of God. He was a man of God who loved his family and his friends. He was a man of God who loved his country and his God. He was a man of God who loved his God and his country. He was a man of God who loved his God and his country. He was a
Analyzing the output generated by the model using greedy search decoding, we notice that while the text was successfully completed, the model repetitively produced the same sentence until reaching the maximum token limit.
Limitations
Greedy search often leads to repetitive sequences, underscoring its limitations.
This limitation is particularly pronounced when diversity is desired in text generation.
The issue arises from the method's emphasis on choosing the highest probability word at each step.
As a result, it overlooks sequences that might have a higher overall probability.
Use Cases
Although the greedy search has shortcomings, it can be effective for tasks that demand deterministic and factually accurate outputs, such as arithmetic problems. Nonetheless, it is less frequently employed for tasks requiring varied or imaginative text.
2. Beam Search Decoding
Beam search introduces a refined approach to token selection in text generation. Beam search is an algorithm used to improve the quality of text generation in models like those based on transformer architecture. It balances the brute-force exactness of exhaustive search and the practical efficiency of greedy search.
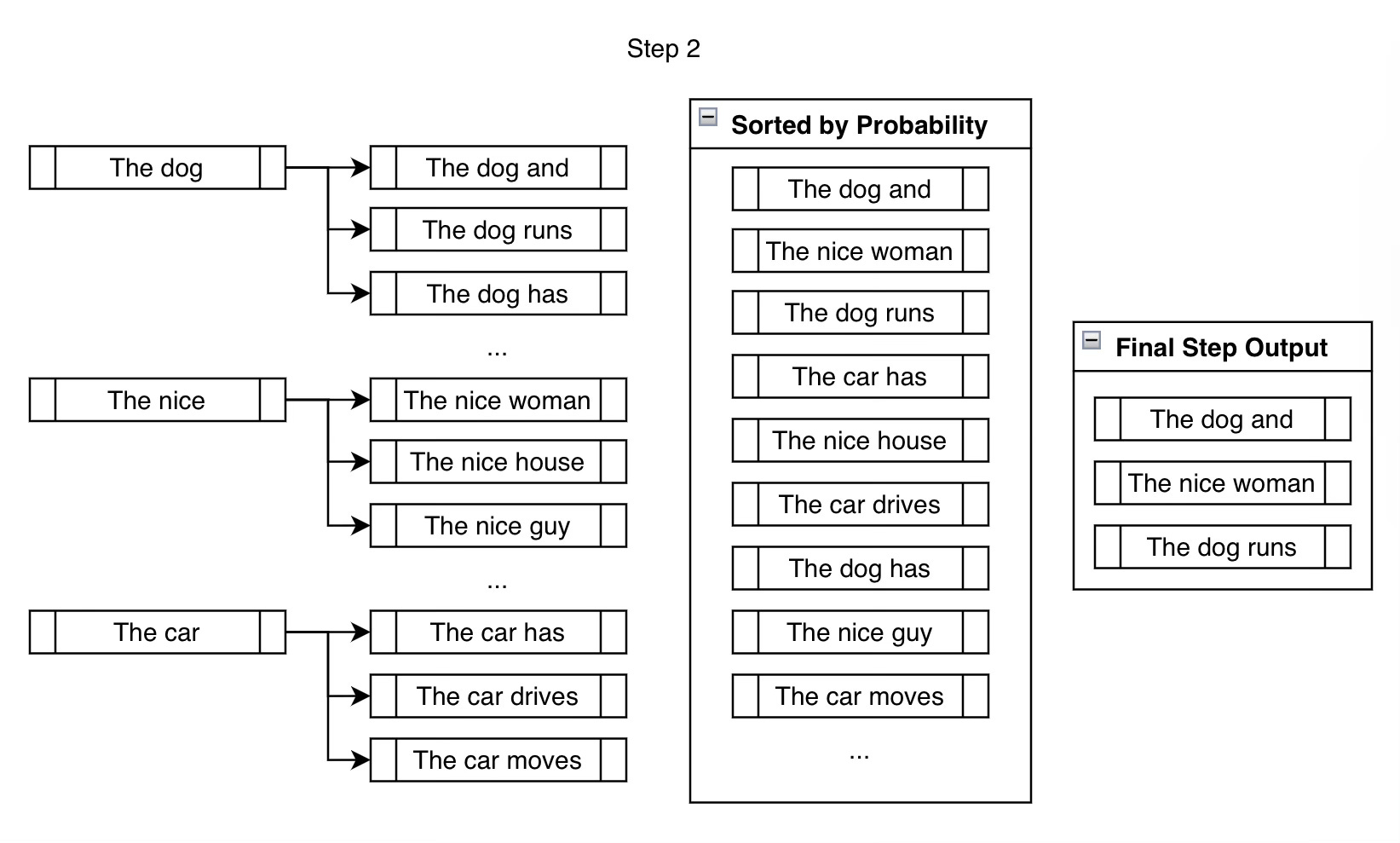
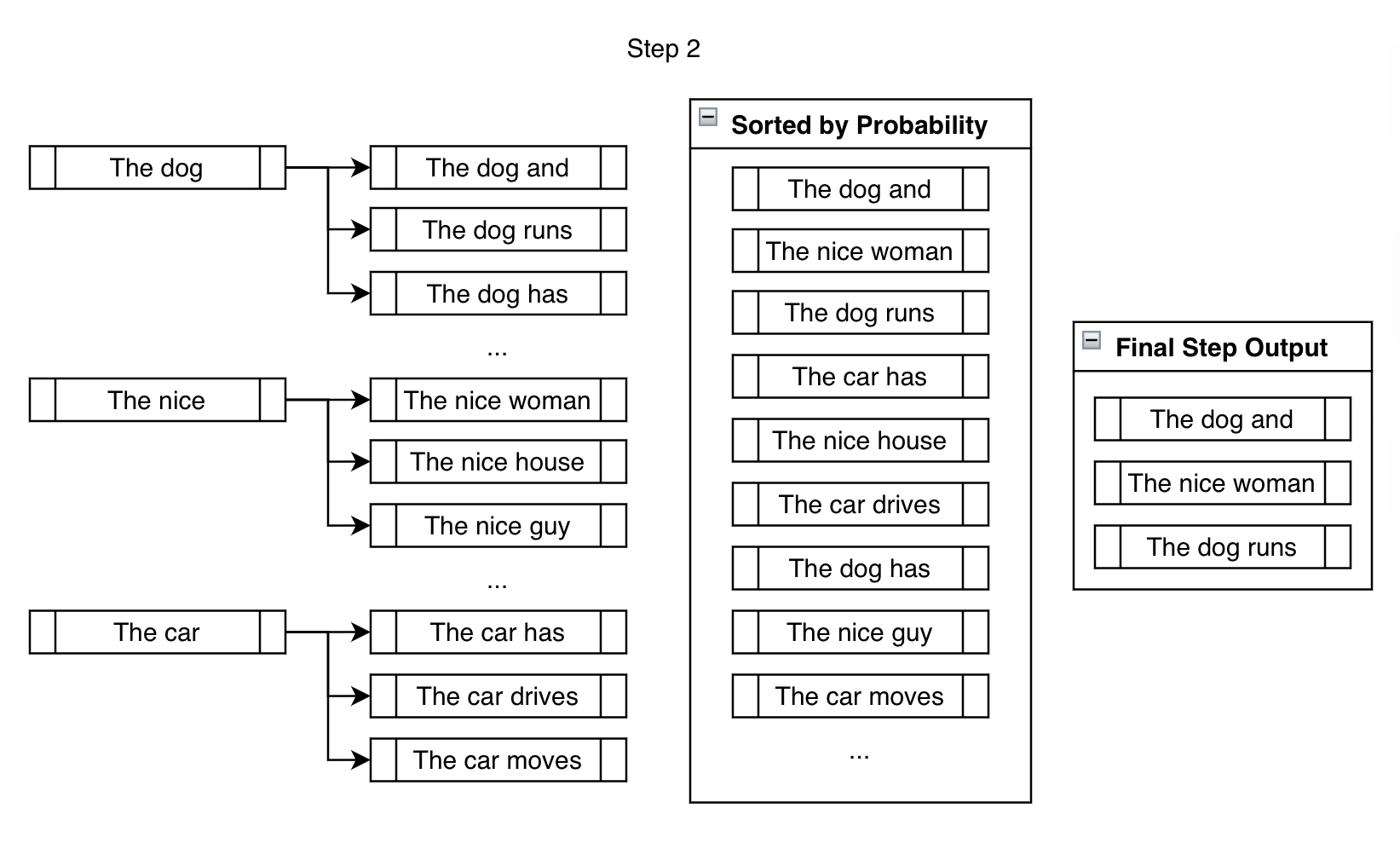
How Beam Search Works
Rather than choosing the highest-probability token at each step, this method maintains the top-b most probable next tokens, where
brepresents the beam width or beam size.It involves evaluating all potential extensions of the current set and selecting the
bmost promising ones. This process is repeated until the maximum number of tokens is reached, ensuring a more balanced search space exploration.
{kind=link}
Implementation
Beam Search can be activated with the generate() function by specifying the num_beams parameter. The more beams we choose, the better the result potentially gets.
Below is an example of how to implement beam search decoding with the GPT-2 XL model using the transformers library:
Case I: With num_beams=5
# Beam Search Decoding with num_beams=5
output = model.generate(input_ids, max_new_tokens=70, num_beams=5, do_sample=False)
generated_text = tokenizer.decode(output[0])
print(generated_text)Code Output:
Once upon a time, there was a man who lived in a small town. He had a wife and two children. One day, he went to the store to buy some milk. When he returned home, he found that his wife and children were gone. He searched for them, but they were nowhere to be found. He went to the police station to report the disappearance of his family
Analyzing the output from beam search decoding reveals that it generated more coherent and clear text. Let’s try another example by increasing the num_beams parameter to 10.
Case II: With num_beams=10
# Beam Search Decoding with num_beams=10
output = model.generate(input_ids, max_new_tokens=70, num_beams=10, do_sample=False)
generated_text = tokenizer.decode(output[0])
print(generated_text)Code Output:
Once upon a time, there was a man who had a dream.
He had a dream that one day he would be able to fly.
He had a dream that one day he would be able to fly.
He had a dream that one day he would be able to fly.
He had a dream that one day he would be able to fly.From the second output, we can see that beam search also suffers from repetitive text. One way to address this is to impose an n-gram penalty with the no_repeat_ngram_size parameter that tracks which n-grams have been seen and sets the next token probability to zero if it would produce a previously seen n-gram, thereby reducing repetitions:
Case I: With num_beams=5 and no_repeat_ngram_size=3
# Beam Search Decoding with num_beams=10 and no_repeat_ngram_size=3
output = model.generate(input_ids, max_new_tokens=70, num_beams=10, do_sample=False, no_repeat_ngram_size=3)
generated_text = tokenizer.decode(output[0])
print(generated_text)Code Output:
Once upon a time, there was a man who lived in a small town. He had a wife, a son, and a daughter. One day, the man went to visit his son in the hospital. When he got there, he found out that his son had died of a heart attack. The man was devastated. He didn't know what to do, so he went to hisWell, from this output, we can observe the generated text is more coherent and clear than the previous output, with num_beams=10.
Limitations
Beam Search suffers from issues like repetitive token generation and bias towards shorter sequences.
The beam search algorithm requires tracking multiple beams at each step, which increases memory usage and computational complexity compared to greedy search.
Use Cases
Beam Search with n-gram penalty is commonly used in applications like summarization and machine translation where factual correctness is emphasised over diversity. Now, let’s explore the text generation technique where we can make the generated text more creative and diverse.
3. Random Sampling
Random sampling is a strategy employed in text generation, particularly in scenarios where diversity is prioritized over factual accuracy, such as story generation or open-domain conversations. Unlike greedy search, which consistently opts for the token with the highest probability, this method introduces an element of randomness to the selection process.
How Random Sampling Works
The model produces a probability distribution for the next token over the entire vocabulary based on the input prompt and the tokens generated.
Instead of choosing the most probable token, a token is randomly selected from this probability distribution, allowing for a broader exploration of possible sequences.
The degree of randomness in sampling can be adjusted using a parameter known as
temperature. Highertemperatureslead to a more uniform distribution, enhancing randomness and diversity. Conversely, a lowertemperatureproduces a sharper distribution, making the output more similar to the highest probability sequence.
Implementation
Random Sampling decoding technique can be activated easily in the transformer’s generate() function by setting the do_sample parameter to True and specify the temperature to control the creativity and diversity of the created text.
Below is an example of how to implement random sampling with the GPT-2 XL model using the transformers library:
Case I: When temperature is high (>1.0)
# Define the input prompt
input_text = "Once upon a time, there was a man who"
input_ids = tokenizer(input_text, return_tensors="pt")["input_ids"].to(device)
# Perform Random Sampling to generate 70 tokens
output = model.generate(input_ids, max_new_tokens=70, do_sample=True, temperature=2.0)
generated_text = tokenizer.decode(output[0])
print(generated_text)Code Output:
Once upon a time, there was a man who liked to cook. Every so often this man visited one part of Egypt more than three different times every fifteen years… until finally they saw him leave Egypt entirely forever, his back into the north… he set himself off somewhere. And on this very lonely place would he spend fifty five years, every generation…
How strange the sound those sixty-In the above output, we can observe that the generated text is very diverse in nature, without any formal plot in the story. This is due to setting the temperature parameter as 2 (i.e. high value)
Case II: When temperature is low (<1.0)
# Random Sampling with temperature=0.7
output = model.generate(input_ids, max_new_tokens=70, do_sample=True, temperature=0.7)
generated_text = tokenizer.decode(output[0])
print(generated_text)Code Output:
Once upon a time, there was a man who made a name for himself in the world. He was handsome, charming, and popular with the ladies, but his wife was not satisfied with his success. She wanted more. She thought she knew what needed to be done, and she was determined to make him do it.Upon reviewing the output above, we can get the gist of the generated text and ensure that it maintains a reasonable level of diversity.
Limitations
The randomness can sometimes result in nonsensical or off-topic text.
The overall quality and coherence of the text might be lower compared to more deterministic methods.
It cannot be used for tasks where factual correctness and deterministic outputs are expected.
Use Cases
Random sampling can be particularly beneficial in creative writing, where text diversity is essential. By introducing an element of unpredictability, it can enhance the narrative's richness and originality. Additionally, random sampling can generate varied responses in text conversations and chatbots. This variability can contribute to a more human-like feel, making users' interactions with these systems more engaging and natural.
Conclusion
Various techniques, such as top-k sampling and nucleus sampling, can enhance the coherence and creativity of the text. The next blog will discuss these techniques in more detail. The notebook for the code provided above can be accessed at this link.
Happy Learning!